Google ha lanzado una aplicación experimental destinada a la búsqueda de contenido en equipos con Windows. Disponible dentro de Search Labs, el programa de pruebas tempranas de la compañía, la herramienta se invoca con el atajo Alt + Espacio y muestra resultados que abarcan aplicaciones instaladas, documentos almacenados en el disco, archivos de Google Drive y enlaces en la web.
La interfaz recuerda por su forma y por su agilidad a otras utilidades similares en macOS –Spotlight-, pero integra elementos propios que la diferencian. Entre ellos está la inclusión de Google Lens, que permite seleccionar elementos visuales en pantalla para traducir texto, resolver ejercicios o ampliar la consulta con imágenes.
La aplicación despliega resultados agrupados en secciones -aplicaciones y sitios web, Drive, archivos locales y web- y permite alternar entre distintos modos, como imágenes, compras o vídeos.
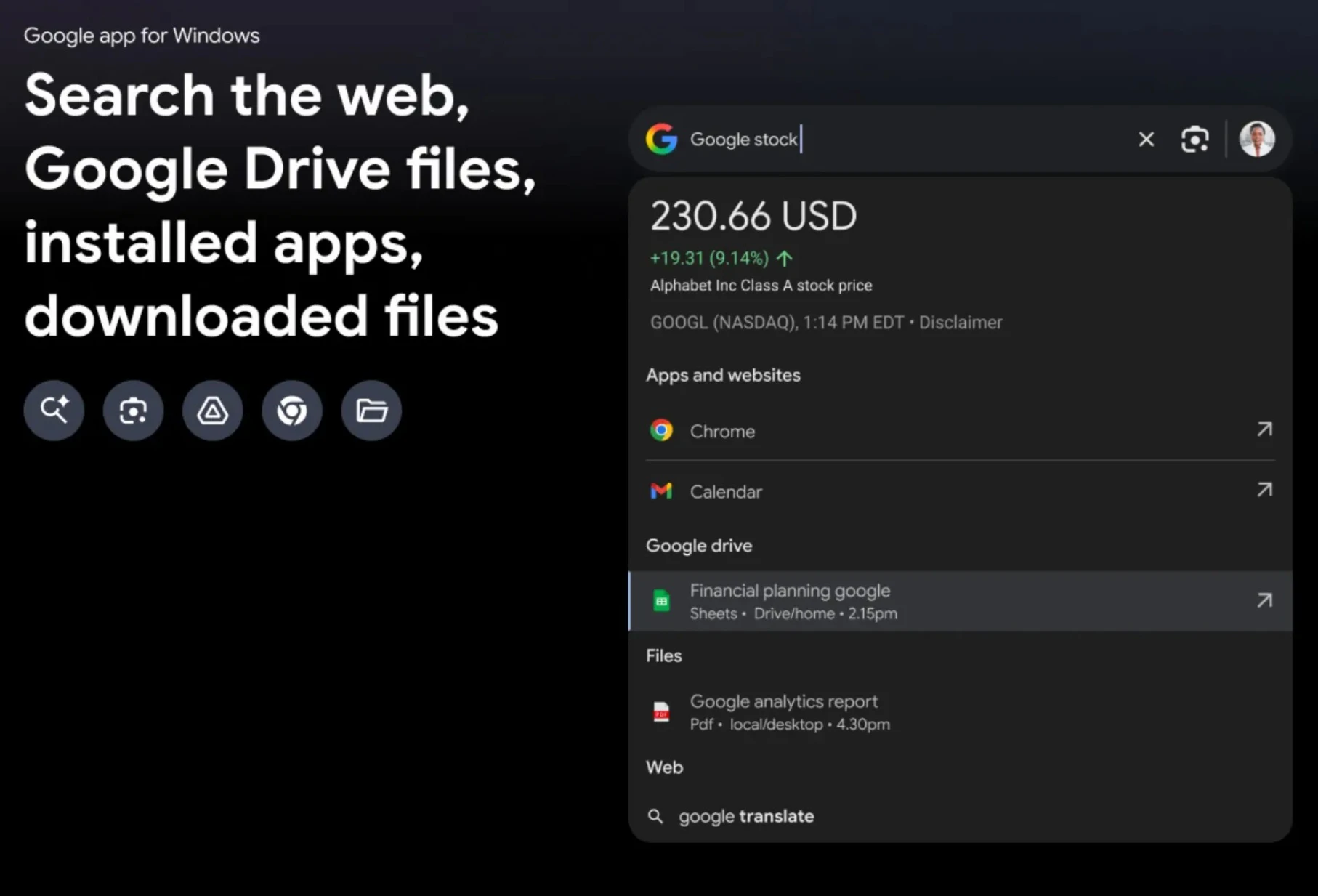
También ofrece un «Modo IA» que presenta respuestas resumidas en lugar de la lista clásica de enlaces, y una vista general con síntesis generada por la inteligencia artificial de Google. Además, se ha incluido la opción de activar un tema oscuro para integrarse mejor con la interfaz del sistema.
Por ahora la descarga está limitada a usuarios en Estados Unidos y la app funciona en inglés; requiere Windows 10 o versiones posteriores. Google recuerda que se trata de una app en fase de pruebas y anima a quien la pruebe a enviar comentarios para pulir su comportamiento.
Detalles de la integración de Lens y el modo IA
La integración de Lens permite señalar un fragmento visual en pantalla y acompañarlo de texto, el usuario obtiene ayuda más rica que la simple correspondencia de términos. Ese flujo resulta útil tanto para traducir pasajes como para resolver dudas matemáticas o identificar objetos mostrados en imágenes.
El Modo IA, por su parte, intenta condensar información compleja en respuestas que faciliten la rápida comprensión, evitando que el usuario tenga que navegar entre múltiples vínculos.
Técnicamente, la app toma elementos ya conocidos de la compañía -como la indexación de Drive y la tecnología de Lens- y los coloca en una interfaz compacta diseñada para activarse con rapidez.