
- Google MusicLM es un modelo de lenguaje innovador que utiliza descripciones de texto para crear composiciones musicales impresionantes sin necesidad de conocimientos musicales.
- MusicLM combina técnicas avanzadas para ofrecer resultados musicales coherentes y personalizados, permitiendo a los usuarios especificar su visión musical a través de texto.
- Desde bandas sonoras emocionantes para videojuegos hasta música relajante basada en lugares, Google MusicLM ofrece una amplia gama de opciones, expandiendo la creatividad musical a nuevos horizontes.
Google MusicLM es un modelo de lenguaje avanzado con el propósito específico de producir composiciones musicales basadas en descripciones textuales. Este modelo innovador se enfoca exclusivamente en el campo de la generación de música y se basa en la base de AudioLM, que fue diseñada para generar continuaciones coherentes de voz y música de piano sin necesidad de transcripciones o representaciones musicales simbólicas.
Funcionalidad de AudioLM y su aplicación en MusicLM
AudioLM convierte el audio de entrada en una serie de tokens discretos, lo que permite al modelo aprender patrones y estructuras inherentes a los datos de audio. MusicLM utiliza una metodología similar, generando música basada en las descripciones de texto proporcionadas. Al ingresar una descripción textual, como «una melodía de guitarra relajante en un riff de compás de 4/4», MusicLM puede producir una composición musical correspondiente que capture la esencia de la descripción.
Componentes y etapas de AudioLM
AudioLM consta de tres etapas jerárquicas:
- Modelado semántico: establece la coherencia estructural a largo plazo al capturar la organización y disposición general de la señal de entrada.
- Modelado acústico grueso: genera tokens acústicos que se concatenan o condicionan en función de los tokens semánticos, estableciendo una representación aproximada del audio.
- Modelado acústico fino: mejora el audio al procesar los tokens acústicos gruesos junto con los tokens acústicos finos, agregando profundidad y complejidad al audio generado.
Modelado autorregresivo y acondicionamiento de texto en MusicLM
MusicLM utiliza el modelado autorregresivo de múltiples etapas de AudioLM como componente generativo, pero amplía esta capacidad al incorporar el acondicionamiento de texto.
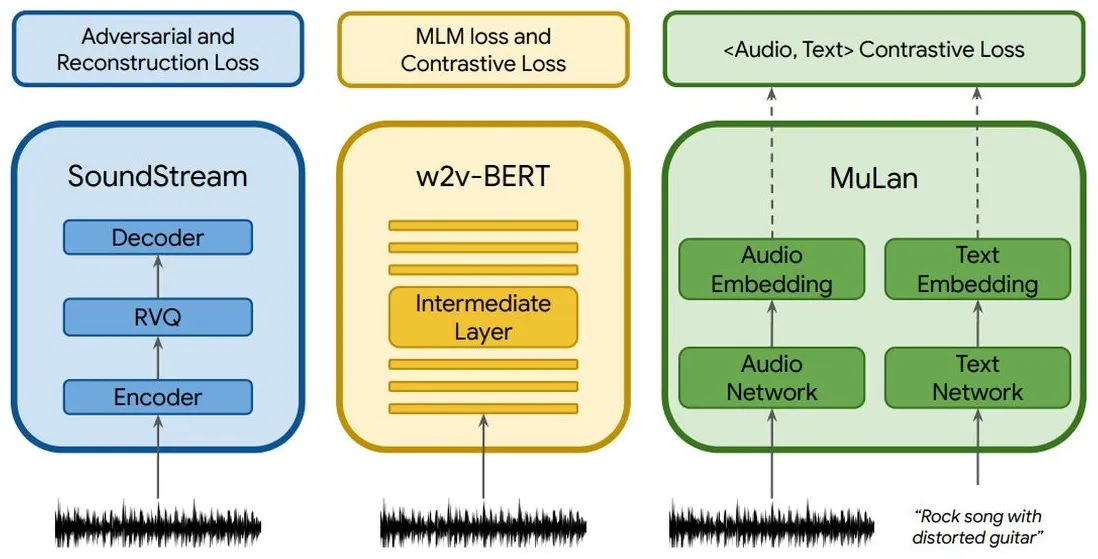
Esto se logra mediante el uso de tres componentes: SoundStream, w2v-BERT y MuLan. SoundStream y w2v-BERT procesan y tokenizan la señal de audio de entrada, mientras que MuLan representa un modelo de integración conjunto para música y texto.
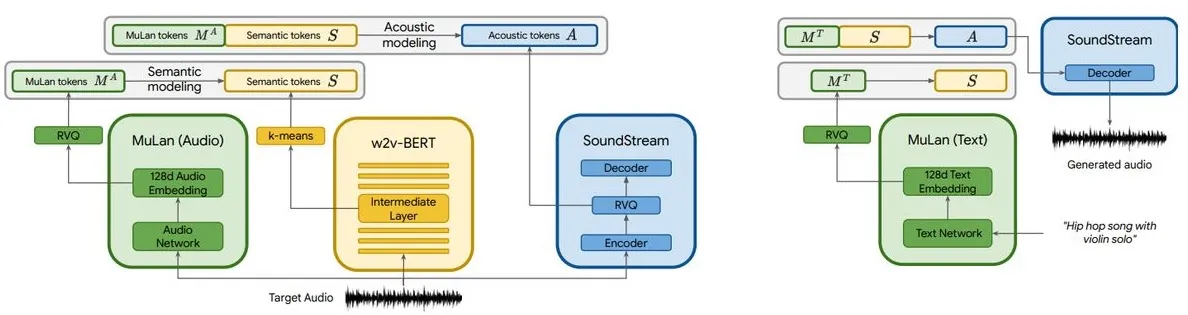
Ventajas y capacidades de MusicLM
MusicLM ofrece tres ventajas distintas:
- Generación basada en descripciones de texto: permite a los usuarios especificar su composición musical deseada mediante texto.
- Acondicionamiento de melodías de entrada: puede utilizar melodías proporcionadas por los usuarios para expandir su funcionalidad y generar música correspondiente.
- Generación de secuencias extendidas de varios instrumentos: sobresale en la generación de composiciones musicales largas y complejas en una amplia gama de instrumentos.
Datos de entrenamiento y disponibilidad de modelos
El conjunto de datos utilizado para entrenar MusicLM consta de aproximadamente 5500 pares de música y texto. Google ha puesto a disposición este conjunto de datos en Kaggle bajo el nombre «MusicCaps». Sin embargo, el gigante tecnológico actualmente no tiene intenciones de distribuir los modelos asociados con MusicLM públicamente, ya que requieren un mayor desarrollo y perfeccionamiento antes de ser compartidos.
Aunque Google no ha distribuido los modelos asociados con MusicLM, ha proporcionado numerosos ejemplos en un libro blanco para demostrar las capacidades del modelo en la generación de música basada en descripciones de texto:
- Descripciones evocadoras: puede generar una banda sonora emocionante para un videojuego lleno de acción con un tempo rápido, ritmos enérgicos y una melodía de guitarra eléctrica contagiosa. La música se caracteriza por patrones repetitivos y elementos inesperados como platillos estruendosos y redobles de tambores dinámicos.
- Duración extendida: tiene la capacidad de generar audio continuo de alta calidad que se extiende hasta 5 minutos. Los usuarios pueden proporcionar indicaciones de texto como «Post-rock triste» o «Hip-hop divertido» para guiar la generación de música, creando una experiencia musical coherente e inmersiva.
- Modo narrativo: permite a los usuarios crear una secuencia musical basada en una historia cohesiva. Por ejemplo, se puede instruir al modelo para que genere una meditación relajante, una transición gradual a un tema de despertar edificante, un ritmo de carrera enérgico y culminar en una sección motivadora y poderosa.
- Acondicionamiento de la melodía y el texto: los usuarios pueden aprovechar esta función para generar música que se alinee con una melodía proporcionada, como un zumbido o un silbido, manteniendo el mensaje de texto deseado. Esto permite convertir una secuencia de audio existente en la representación de audio deseada.
- Temas basados en la ubicación: puede generar música basada en descripciones de lugares o entornos específicos. Por ejemplo, se puede capturar el ambiente sereno y soleado de un día tranquilo en la playa, utilizando este mensaje de texto para generar música que encapsule el estado de ánimo y la atmósfera del entorno.